08/21/2024
- Rustcask
- Design
- Rustcask vs. Log-Structured Merge-Trees (LSM-trees) like LevelDB
- Performance
- Usage
- What's next?
Rustcask
I recently released Rustcask to Github and crates.io.Rustcask is a fast and efficient key-value storage engine implemented in Rust. It's based on Bitcask, "A Log-Structured Hash Table for Fast Key/Value Data".
Here are some interesting sections that I've copied from the README on Github:
Design
Bitcask
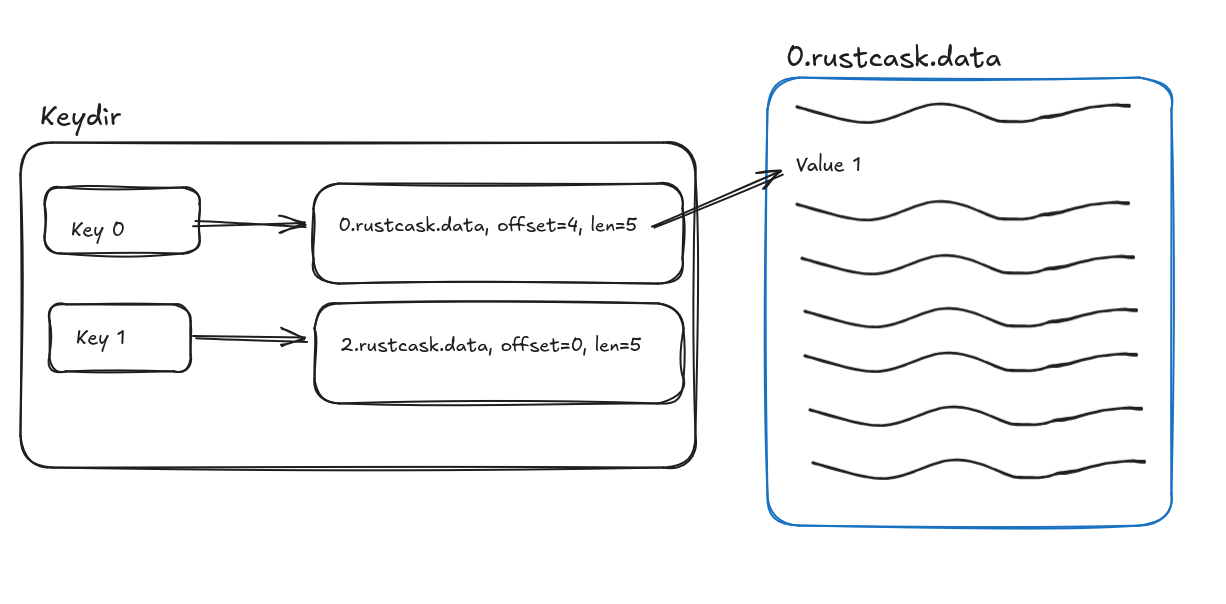
Rustcask follows the design of Bitcask very closely. A Rustcask directory is composed of data files. At any time, there is only one active data file. Writes are appended to that data file, and once it reaches a certain size, the file is closed and marked read-only.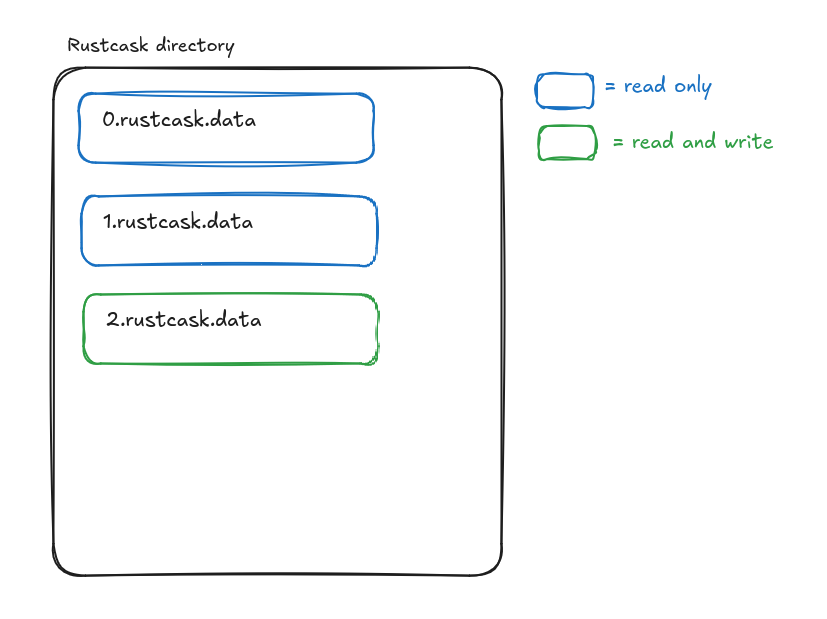 An in-memory data structure (see keydir.rs) maps each key to the data file and offset of the
most recently written value for that key. This means that reads require only a single disk seek.
On restarts, Rustcask traverses data files within the Rustcask directory to rebuild the keydir.
An in-memory data structure (see keydir.rs) maps each key to the data file and offset of the
most recently written value for that key. This means that reads require only a single disk seek.
On restarts, Rustcask traverses data files within the Rustcask directory to rebuild the keydir.
 By writing values to disk sequentially, Bitcask and Rustcask are able to achieve high write throughput.
However, this append-only strategy means that stale (overwritten) values accumulate in the data files. This is why Bitcask and Rustcask
provide a merge function, which compacts data files and removes stale keys. In production environments, managing background data file compaction
without affecting the key-value store's performance is a tricky problem.
By writing values to disk sequentially, Bitcask and Rustcask are able to achieve high write throughput.
However, this append-only strategy means that stale (overwritten) values accumulate in the data files. This is why Bitcask and Rustcask
provide a merge function, which compacts data files and removes stale keys. In production environments, managing background data file compaction
without affecting the key-value store's performance is a tricky problem.
Rustcask vs. Log-Structured Merge-Trees (LSM-trees) like LevelDB
What are the benefits of Rustcask over LSM-tree-based storage engines?
Rustcask's design is much simpler than LSM-tree storage engines like LevelDB. As such, it's an easy code base to maintain.Additionally, Rustcask has less read amplification than LevelDB. For example, as described in the WiscKey paper, LevelDB has high read amplification because you may have to read up to 14 SSTable files to find the data you're looking for. In Rustcask, we store the entire keydir in memory, which means that reads require only a single seek.
What are the benefits of LSM-trees like LevelDB over Rustcask
Rustcask stores the entire key-set in memory. If your key-set won't fit in memory, then LevelDB is a much better alternative because LevelDB stores a sparse index of the key-set in memory.LevelDB also supports efficient range queries because it writes values to disk in sorted order. Rustcask does not.
And finally, LevelDB is likely much more efficient in how it manages the background compaction process.
Performance
I used the Divan crate for benchmarking Rustcask. The benchmarks that I wrote are stored under the benches directory.I've found that for write-heavy workloads, I'm able to achieve a write bandwidth that is very close to the max write bandwidth my disk supports: On my local desktop, I have a disk that supports up to 560 MB/s of sequential write throughput. The bench_writes workload shows that Rustcask is able to achieve up to 503 MB/s of write throughput.

Read workloads also perform well, as they require only a single disk seek, and the operating system's caching layers eliminate many disk accesses anyways.
Usage
For examples of usage, see the integration tests, or the performance tests. The cargo documentation is also available at docs.rs/rustcask. Here is a simple set-get example:
Synchronous mode
By default, writes to Rustcask are not immediately flushed to disk. This improves performance because the operating system can batch writes to disk. However, you can force Rustcask to immediately flush all writes to disk by enabling sync mode: